Root-finding algorithm
-is a numerical method, or algorithm, for finding a value x such that f(x) = 0, for a given function f. Such an x is called a root of the function f.
This article is concerned with finding scalar, real or complex roots, approximated as floating point numbers. Finding integer roots or exact algebraic roots are separate problems, whose algorithms have little in common with those discussed here. (See: Diophantine equation as for integer roots)
Finding a root of f(x) − g(x) = 0 is the same as solving the equation f(x) = g(x). Here, x is called the unknown in the equation. Conversely, any equation can take the canonical form f(x) = 0, so equation solving is the same thing as computing (or finding) a root of a function.
Numerical root-finding methods use iteration, producing a sequence of numbers that hopefully converge towards a limit (the so called "fixed point") which is a root. The first values of this series are initial guesses. The method computes subsequent values based on the old ones and the function f.
The behaviour of root-finding algorithms is studied in numerical analysis. Algorithms perform best when they take advantage of known characteristics of the given function. Thus an algorithm to find isolated real roots of a low-degree polynomial in one variable may bear little resemblance to an algorithm for complex roots of a "black-box" function which is not even known to be differentiable. Questions include ability to separate close roots, robustness in achieving reliable answers despite inevitable numerical errors, and rate of convergence.
Specific algorithms
The simplest root-finding algorithm is the bisection method. It works when f is a continuous function and it requires previous knowledge of two initial guesses, a and b, such that f(a) and f(b) have opposite signs. Although it is reliable, it converges slowly, gaining one bit of accuracy with each iteration.
Newton's method assumes the function f to have a continuous derivative. Newton's method may not converge if started too far away from a root. However, when it does converge, it is faster than the bisection method, and is usually quadratic. Newton's method is also important because it readily generalizes to higher-dimensional problems. Newton-like methods with higher order of convergence are the Householder's methods. The first one after Newton's method is Halley's method with cubic order of convergence.
Replacing the derivative in Newton's method with a finite difference, we get the secant method. This method does not require the computation (nor the existence) of a derivative, but the price is slower convergence (the order is approximately 1.6).
The false position method, also called the regula falsi method, is like the secant method. However, instead of retaining the last two points, it makes sure to keep one point on either side of the root. The false position method is faster than the bisection method and more robust than the secant method, but requires the two starting points to bracket the root.
The secant method also arises if one approximates the unknown function f by linear interpolation. When quadratic interpolation is used instead, one arrives at Müller's method. It converges faster than the secant method. A particular feature of this method is that the iterates xn may become complex.
This can be avoided by interpolating the inverse of f, resulting in the inverse quadratic interpolation method. Again, convergence is asymptotically faster than the secant method, but inverse quadratic interpolation often behaves poorly when the iterates are not close to the root.
Finally, Brent's method is a combination of the bisection method, the secant method and inverse quadratic interpolation. At every iteration, Brent's method decides which method out of these three is likely to do best, and proceeds by doing a step according to that method. This gives a robust and fast method, which therefore enjoys considerable popularity.
Finding multiple roots
If p(x) is a polynomial with a multiple root at r, then finding the value of r can be difficult (inefficient or impossible) for many of the standard root-finding algorithms. Fortunately, there is a technique especially for this case, provided that p is given explicitly as a polynomial in one variable with exact coefficients.
Algorithm
- First, we need to determine whether p(x) has a multiple root. If p(x) has a multiple root at r, then its derivative p′(x) will also have a root at r (one fewer than p(x) has there). So we calculate the greatest common divisor of the polynomials p(x) and p′(x); adjust the leading coefficient to be one and call it g(x). (See Sturm's theorem.) If g(x) = 1, then p(x) has no multiple roots and we can safely use those other root-finding algorithms which work best when there are no multiple roots, and then exit.
- Now suppose that there is a multiple root. Notice that g(x) will have a root of the same multiplicity at r that p′(x) has and the degree of the polynomial g(x) will generally be much less than that of p(x). Recursively call this routine, i.e. go back to step #1 above, using g(x) in place of p(x). Now suppose that we have found the roots of g(x), i.e. we have factored it.
- Since r has been found, we can factor (x−r) out of p(x) repeatedly until we have removed all of the roots at r. Repeat this for any other multiple roots until there are no more multiple roots. Then the quotient, i.e. the remaining part of p(x), can be factored in the usual way with one of the other root-finding algorithms. Exit.
Example
Suppose p(x) = x3+x2−5x+3 is the function whose roots we want to find. We calculate p′(x) = 3x2+2x−5. Now divide p′(x) into p(x) to get p(x) = p′(x)·((1/3)x+(1/9))+((−32/9)x+(32/9)). Divide the remainder by −32/9 to get x−1 which is monic. Divide x−1 into p′(x) to get p′(x) = (x−1)·(3x+5)+0. Since the remainder is zero, g(x) = x−1. So the multiple root of p(x) is r = 1. Dividing p(x) by (x−1)2, we get p(x) = (x+3)(x−1)2 so the other root is −3, a single root.
Algebraic geometry
The performance of standard polynomial root-finding algorithms degrades in the presence of multiple roots. Using ideas from algebraic geometry, Zhonggang Zeng has published a more sophisticated approach, with a MATLAB package implementation, that identifies and handles multiplicity structures considerably better. A different algebraic approach including symbolic computations has been pursued by Andrew Sommese and colleagues, available as a preprintPDF). (
Direct algorithm for multiple root elimination
There is a direct method of eliminating multiple (or repeated) roots from polynomials with exact coefficients (integers, rational numbers, Gaussian integers or rational complex numbers).
Suppose a is a root of polynomial P, with multiplicity m>1. Then a will be a root of the formal derivative P ’, with multiplicity m−1. However, P ’ may have additional roots that are not roots of P. For example, if P(x)=(x−1)3(x−3)3, then P ’(x)=6(x−1)2(x−2)(x−3)2. So 2 is a root of P ’, but not of P.
Define G to be the greatest common divisor of P and P ’. (Say, G(x) = (x−1)2(x−3)2).
Finally, G divides P exactly, so form the quotient Q =P/G. (Say, Q(x)= (x−1)(x−3) ). The roots of Q are the multiple roots of P.
As P is a polynomial with exact coefficients, then if the algorithm is executed using exact arithmetic, Q will also be a polynomial with exact coefficients.
Obviously degree(Q) <>P). If degree(Q) ≤ 4 then the multiple roots of P may be found algebraically. It is then possible to determine the multiplicities of those roots in P algebraically.
Iterative root-finding algorithms perform well in the absence of multiple roots.
Transcendental Equation
A transcendental equation is an equation containing a transcendental function. Examples of such an equation are
- x = e − x
- x = sin(x)
Solution methods
Some methods of finding solutions to a transcendental equation use graphical or numerical methods. For a graphical solution, one method is to set each side of a single variable transcendental equation equal to a dependent variable (for example, y) and plot the two graphs, using their intersecting points to find solutions. The numerical solution extends from finding the point at which the intersections occur using some kind of numerical calculations (calculator or math software). Approximations can also be made by truncating the Taylor series if the variable is considered to be small. Additionally, Newton's method could be used to solve the equation.
Often special functions can be used to write the solutions to transcendental equations in closed form. In particular, the first equation has a solution in terms of the Lambert W Function.




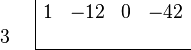

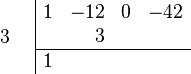




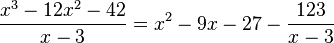







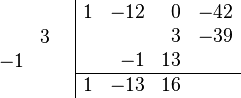

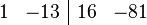
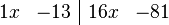
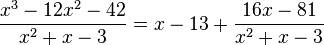









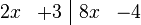

 We can condense the notation a bit by writing it in terms of an
We can condense the notation a bit by writing it in terms of an  . So then we have
. So then we have 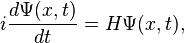 where we have to keep in mind that
where we have to keep in mind that  . We've removed the imaginary number from the time derivative and added in a constant offset of
. We've removed the imaginary number from the time derivative and added in a constant offset of 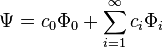 Since this is a
Since this is a 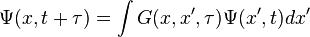 . Similarly to classical mechanics, we can only propagate for small slices of time; otherwise the Green's function is inaccurate. As the number of particles increases, the dimensionality of the integral increases as well, since we have to integrate over all coordinates of all particles. We can do these integrals by
. Similarly to classical mechanics, we can only propagate for small slices of time; otherwise the Green's function is inaccurate. As the number of particles increases, the dimensionality of the integral increases as well, since we have to integrate over all coordinates of all particles. We can do these integrals by 